Introduction
In a presentation of some time ago [1], I had highlighted the importance
of the control between the reference day and the expected one of a data file
received from the host system. Given the importance of the topic, I would
further deepen both the meaning of the control and the identification of the
reference day of the data.
This argument may seem strange, or too technical, mainly for those who
are not very experienced about Data Warehouse, or for those they are to his
first experience. I'll try to simplify the concept it as much as possible,
because this it is a very useful example to understand the pitfalls inside the
ETL process.
Example
To understand the problem, we assume a similar example of practical
life. Suppose that you receive every morning, from your bank, via email, the
list of the operations of your checking account.
So, you receive daily an excel spreadsheet with the movements of the
previous day. The reference day of the operations, is located in the subject of
the email, for example: "Operations of the 03/12/2015".
Obviously you do not check your email from the bank every morning: you
have created an automatic mechanism that opens the email, and load the daily
operations, with the day indicated in
the subject of the email, in the database of your household expenses. Only at
the start of the month, you start to do your analysis about the previous month.
The questions are:
What guarantees do you have, that the email arrive to you every day?
What guarantee do you have that the day, in the subject of the email,
definitely makes always reference to the day before?
The importance of the
control
If we are not able to answer the questions above, we have no guarantee about
the validity of our analysis.
This is the reason why the control is important. That's why we have to
be absolutely sure that the day that we are loading is exactly what we
expected. And, before that, we have to verify that what we expected, has
arrived. We should not assume that everything spins smoothly, because it is
always possible that an anomaly occurs. Both in the source systems that in our
systems.
Do not forget, that in the face of a problem, we are always us,
understood as the Data Warehouse team, the first interlocutors, the first
people to which requires explanation. In practice, in the eyes of end-users, we
are the cause of the problem. Those who had to control and they did not it.
Here are two examples that may occur. (and in fact they are occurred to me in
the past).
Problem 1
In the source system there has been some revision or changes in the
extraction plans (no one is forced to alert you), so an error rises in the data
filter. Consequence: the data file is daily generated correctly, but the
reference day inside the flow is wrong. We don't know the cause. The reference
day may remain fixed, backward a day, equal to the system date, or refers to a
field different from the previous data file. Only if we check the reference day
with the expected day we realize the error.
Problem 2
The ETL process, via ftp, copies the file from the host system folder to
a local folder to process it. Suppose that the host folder, which is a folder
also used by other systems, for reasons of maintenance or space, starting from
a certain day, is no longer used, replaced by another folder. Nobody warns you,
the old folder is still visible, and the Data Warehouse, the day after the
exchange, continues to feed itself from the old folder. Also in this case, to
have an immediate control of the reference day is crucial.
Moreover, if the data you are loading erroneously always for the same
day, are mixed with other data that instead change daily, discover this kind of
error cannot be immediate and may take several days.
The solution
The proposed solution to control the congruence between the reference
day and the expected one, was very minimal, according to the rules of an
"agile" vision for the construction of a Data Warehouse [2]. Were
sufficient a metadata table and a log table. We can graphically represent its
logic in the following figure. In practice, we can use a configuration table,
of "calendar" type. In it, each calendar day, is associated with the
expected day of the daily data source
and with the reference day loaded.
A log table shows, at the end of the daily load, the congruence of the
two days. The physical names are constructed according my standard of naming
convention.

The basic elements
The elements involved in this control are thus three. The first is the
calendar day. The second is the awaited day inside the daily flow. We must
configure it on the basis of the flow
analysis. We know their logic, so we can easily configure the awaited day. For
example, if the data file is not expected at the weekend, the saturdays and the
sundays of the calendar will not be setted as expected days.
The third element in the game is the reference day inside the data file.
That is the day to be compared with that expected for the verification of
congruence.
The reference day of
the data
Now focus your attention to the third element, the reference day of the
data . Where is this information?
It would be nice to think to a rule that the day is always present
directly as a column of the file. This should be a rule, an underlying
condition.
Unfortunately in a Data Warehouse, as usual, nothing is simple, and the
reference day, most of the time, is not a column of the data file. The rule
that we have described, it may be applied only if we are lucky enough to be
able to decide ourselves the structure of the source files. Most often, though,
we'll have to re-use (to save money, of course) data files already existing,
created with different rules. Let's see what are the situations that surely we
will face.
- The day is a column of the data file
- The day is in the header of the data file
- The day is in the tail of the data file
- The day is in the data file name
- The day, there is not.

The day is a column
of the data file
This is the most simple and easily manageable case. The day is a column
of the data file. For example, a recording date, an execution date of an order,
a fiscal date. Typically you can find this situation in the data files that
will become, at the end of the ETL process, the fact tables.
The day is in the
header/tail of the data file
Typically you can find this situation in standardized flows, already
present, generated on the mainframe, by programs written with Cobol language.
These files can have various lines in the header/tail with a lot of information
in it, including the reference day. In fact, the reference day, usually, is the
date of the generation of the data file. However, if the data are of anagraphical
type (like the features of the customers), we can think that it is the same of
the reference day.
Think of a customer data file. If the data extraction start at 22.00 of
the day 2015/03/31, we may think that it freezes the daily situation of the
customers at the 2015/03/31; therefore the extraction day is the same of the
reference day. Caution, however, the cases in which the extraction starts after
the midnight. In this case, the reference day is equal to the extraction day
minus 1 day.
The reference day is
inside the file name
This is a fairly common event, typical above all for data files in csv
format.
The reference day is missing
We must also consider this
case. Sometimes the data file is generated with the same name, (therefore
exclude the case above), may have a header/tail, but without the information
that interests us. We can only rely on the system date of the Data Warehouse
server.
The importance of the metadata
Let us now see how to
provide a method to handle these situations. It is easily implemented using
only a bit of the language of the database (for example, the pl/sql of Oracle,
but these techniques can easily be adapted to any database) and a bit of
metadata.
Metadata, logical term
very sophisticated and intriguing, that hides what we call trivially
configuration tables, are essential to manage the case studies we have described.
The metadata needed to identify and extract the reference day are:
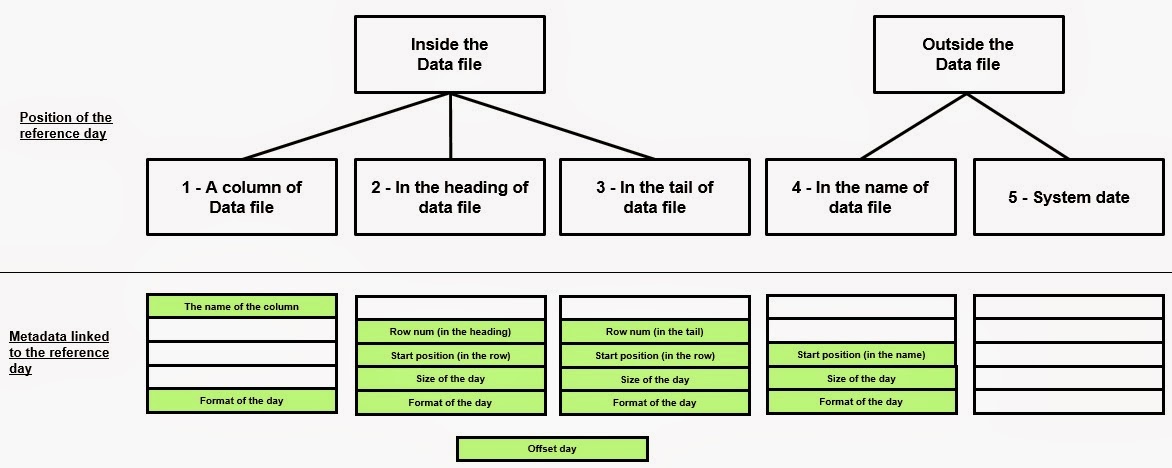
- ref_day_cod = fits here, if
there is, the name of the
column that contains the reference
day.
- row_num = with this number
we denote the offset of the line, from the beginning of the data file, if
it is in the header, in which we find the reference day. The number will
be negative in the case where the reference day is in the tail.
- start_num = with this number
we indicate, within the row_num, the position of the starting character of
the reference day.
- size_num = with this number
we indicate the size of the day. If in the YYYYMMDD format, will be 8, in
the DD-MM-YYYY format is 10. Avoid using the months in text format.
- for_txt = with this string
we indicate the date format of the reference day. For example 'yyyy-mm-dd'.
- off_num = with this number
we indicate the offset (in days) of the reference date. This information
is useful in the case where the generation of the flow and its processing
is performed on different days. Let's take an example. Today is the day 14
and start the processing of the
data file. The flow was generated yesterday at 22:00, The day 13 is in the
header, and we assume that this is the day of the reference data. In this
case off_num must be equal to zero. Suppose now that the generation of the
data file takes place after midnight, for which we find in the header the
day 14. In this case off_num must be set = -1, because even if the
generation and processing of the flow occurred after midnight definitely
the master data refer to the situation of the day 13. This, in brief, is
the need for this metadata.
Now complete the previous figure with an
example of the corresponding data files.

How to use the metadata
Define the metadata, place
them in a configuration table of all data files and fill the content, it is not
a "passive" activity . That is, not only serves to document the
structure of the data files, but it is also "active" information,
because it can be used in the ETL programs.
Let's take a concrete
example very simple. A data file, it is only a sequence of lines structured in
data columns. We can represent it as:

The first thing to do in
order to load the data file into the Staging Area is to build an external table
that "sees" the data file, with the same columns plus the technical
field <IO> _row_cnt, that simply gives a number to each row. <IO>
is the input file code.
The Staging Area table
must obviously have the same columns of the external table plus the reference
day DAY_COD. If the day is already in the data file, it does not matter. Always
insert an additional DAY_COD column. At this point, you can create a function
that, having as input the IO_COD, uses the metadata table and extracts the
value of the reference day to be loaded in the DAY_COD of the Staging Area
table.

Conclusion
I have already had occasion to emphasize the importance of the reference
day of the data. A mistake on his identification may jeopardize the validity of
the whole Data Warehouse. Do not forget that:
the versioning policies of the dimensional tables (slowly changing
dimension of type 2) are based on the reference day.
the fact tables are partitioned using the reference day. An error in the
initial phase can be very costly in the following stages of the project. So,
beyond the technical solution, the identification and control of the reference
day is a very important issue in a Data Warehouse project.
The management of the reference day, just as the "NULL"
management[3] and as the description of the codes [4], which I have already
spoken at length, seem unimportant arguments and of little interest.
But, to ignore them, is very dangerous, and may be the cause of many
failures in the worst case. Or heavy delays in the deploy in the best cases.
References
[2] http://www.slideshare.net/jackbim/recipe-11-agile-data-warehouse-and-business-intelligence
No comments:
Post a Comment